 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友jmyhyu
发布时间:2022-01-07
[主观题]
关于“非结构化数据(文档)的查找与搜索”问题,参考下图,回答下列问题。注意每份文档可能包含数千数万的词汇。
关于“非结构化数据(文档)的查找与搜索”问题,参考下图,回答下列问题。注意每份文档可能包含数千数万的词汇。 若要在n个全文文档中(n可能很大)查找与某个关键词最相关的文档,为提高检索效果和检索效率,最好的做法是_____。
若要在n个全文文档中(n可能很大)查找与某个关键词最相关的文档,为提高检索效果和检索效率,最好的做法是_____。
若要在n个全文文档中(n可能很大)查找与某个关键词最相关的文档,为提高检索效果和检索效率,最好的做法是_____。A、对这n个文档,首先建立一个“关键词”索引表,该索引表记录着“关键词”及包含该关键词的“文档编号”,并按关键词进行字母序的排序。在此基础上,用给定关键词来匹配索引表中的关键词。如果匹配成功,则输出索引表中相对应的文档编号,否则,则输出信息“没有含该关键词的文档”
B、对这n个文档,首先建立一个“关键词”索引表,该索引表记录着“关键词”,包含该关键词的“文档编号”,以及该关键词在该文档中出现的“次数”,并按关键词进行字母序的排序。在此基础上,用给定关键词来匹配索引表中的关键词。如果匹配成功,则进一步寻找同一关键词“次数”最多的m个索引项,输出相对应的文档编号;否则,则输出信息“没有含该关键词的文档”
C、对这n个文档,首先建立一个“关键词”索引表,该索引表记录着“关键词”,包含该关键词的“文档编号”,以及该关键词在该文档中出现的“次数”;对索引表,按关键词进行字母序的排序;如果关键词相同,则进一步按“次数”对同一关键词的若干文档进行降序排序。在此基础上,用给定关键词来匹配索引表中的关键词。如果匹配成功,则进一步寻找同一关键词“次数”最多的m个索引项,输出相对应的文档编号;否则,则输出信息“没有含该关键词的文档”
D、选项(B)(C)比选项(A)的做法好,但选项(B)(C)在执行效果和执行效率方面没有什么差别
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
 抱歉!暂无答案,正在努力更新中……
抱歉!暂无答案,正在努力更新中……

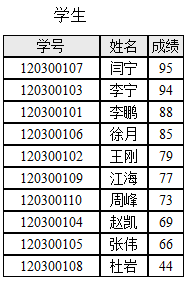 【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 针对按成绩降序排列的数据表,假设记录数为n,关于算法A2,下列说法正确的是_____。
【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 针对按成绩降序排列的数据表,假设记录数为n,关于算法A2,下列说法正确的是_____。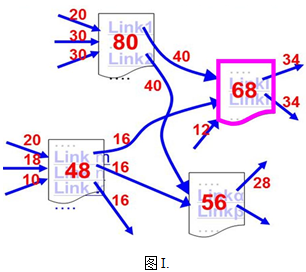 前述说过 PageRank网页i重要度
前述说过 PageRank网页i重要度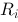 可以通过迭代地计算得到,即由m-1状态下各个网页的重要度
可以通过迭代地计算得到,即由m-1状态下各个网页的重要度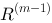 ,依转移概率矩阵计算m状态下网页重要度
,依转移概率矩阵计算m状态下网页重要度 ,参见下图。
,参见下图。 关于网页重要度的计算过程,下列说法正确的是_____。
关于网页重要度的计算过程,下列说法正确的是_____。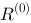 ,是一向量,参见下图,继续进行(B)
,是一向量,参见下图,继续进行(B)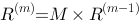 ,m从0开始,为迭代次数。当
,m从0开始,为迭代次数。当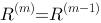 时,迭代计算终止,此时的向量R即为所求的各个网页的重要度
时,迭代计算终止,此时的向量R即为所求的各个网页的重要度




























