 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友wzhuqi
发布时间:2022-01-06
[主观题]
对给定关键字序号j(1<j<n),要求在无序记录A[1..n]中找到关键字从小到大排在第j位上的记录,写一个
对给定关键字序号j(1<j<n),要求在无序记录A[1..n]中找到关键字从小到大排在第j位上的记录,写一个算法利用快速排序的划分思想实现上述查找(要求用最少的时间和最少的空间)。例如:给定无序关键字{7,5,1,6,2,8,9,3),当j=4时,找到的关键字应是5。【中科院研究生院2003十二(15分)】【武汉理工大学2002四、3(35/3分)】
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
查看官方参考答案

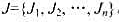 .每个作业Ji都有2项任务分别在2台机器上完成.每个作业必须先由机器1处理,再由机器2处理.作业Ji需要机器j的处理时间为tij(=1,2,...,n;j=1,2).对于一个确定的作业调度,设Fij是作业i在机器j上完成处理的时间.所有作业在机器2上完成处理的时间和
.每个作业Ji都有2项任务分别在2台机器上完成.每个作业必须先由机器1处理,再由机器2处理.作业Ji需要机器j的处理时间为tij(=1,2,...,n;j=1,2).对于一个确定的作业调度,设Fij是作业i在机器j上完成处理的时间.所有作业在机器2上完成处理的时间和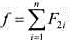 称为该作业调度的完成时间和.
称为该作业调度的完成时间和.





























