题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友hanfengr
发布时间:2022-01-07
[单选题]
已知A=50;B=40;C=100;D=30,计算表达式(A * A - B * B) + D的值,结果为_____。
A.930
B.750
C.150
D.570
 参考答案
参考答案
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
查看官方参考答案
 网友提供的答案
网友提供的答案
共位网友提供了参考答案,
查看全部
- · 有4位网友选择 C,占比36.36%
- · 有4位网友选择 A,占比36.36%
- · 有2位网友选择 B,占比18.18%
- · 有1位网友选择 D,占比9.09%



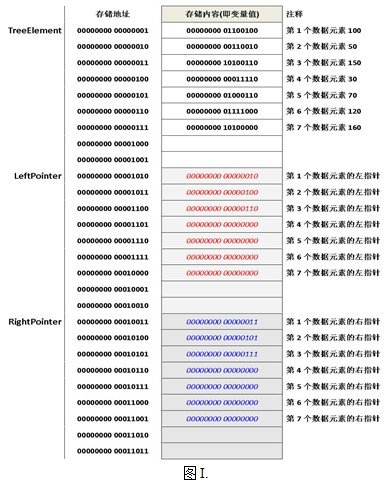 上图(I)表示的数据的逻辑关系,下列正确的是_____。
上图(I)表示的数据的逻辑关系,下列正确的是_____。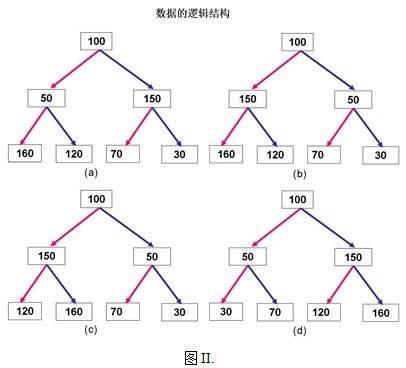
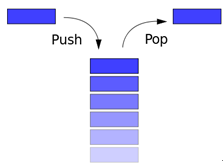 有关堆栈数据结构的基本运算,说法不正确的是_____。
有关堆栈数据结构的基本运算,说法不正确的是_____。
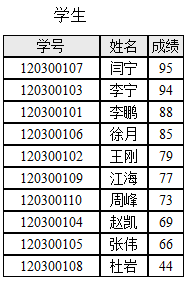 【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 针对上述三个算法,回答问题:关于算法A3和算法A1,下列说法正确的是_____。
【算法A1】 Start of algorithm A1 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果是,则输出;如果不是,则不输出。 End of algorithm A1 【算法A2】 Start of algorithm A2 Step 1. 从数据表的第1条记录开始,直到其最后一条记录为止,读取每一条记录,做Step 2和Step 3。 Step 2. 对每一条记录,判断成绩是否等于给定的分数:如果等于,则输出;如果不等于,则不输出。 Step 3. 判断该条记录的成绩是否小于给定的分数:如果不是,则继续;否则,退出循环,算法结束。 End of algorithm A2 【算法A3】 Start of algorithm A3 Step 1. 假设数据表的最大记录数是n,待查询区间的起始记录位置Start为1,终止记录位置Finish为n; Step 2. 计算中间记录位置I = (Start+Finish)/2,读取第I条记录。 Step 3. 判断第I条记录的成绩与给定查找分数: (3.1)如果是小于关系,则调整Finish = I-1;如果Start >Finish则结束,否则继续做Step 2; (3.2)如果是大于关系,则调整Start = I+1;如果Start>Finish则结束,否则继续做Step 2; (3.3)如果是等于关系,则输出,继续读取I周围所有的成绩与给定查找条件相等的记录并输出,直到所有相等记录查询输出完毕则算法结束。 End of algorithm A3 针对上述三个算法,回答问题:关于算法A3和算法A1,下列说法正确的是_____。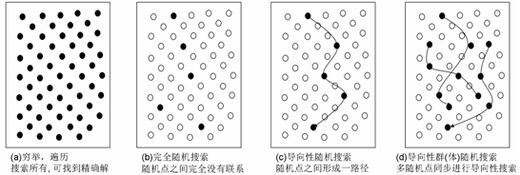 遗传算法是典型的计算求解的方法,它通过“产生任何一个可能解,并验证可能解的正确性”的方法求解一个复杂问题。关于计算求解,下列说法正确的是_____。
遗传算法是典型的计算求解的方法,它通过“产生任何一个可能解,并验证可能解的正确性”的方法求解一个复杂问题。关于计算求解,下列说法正确的是_____。
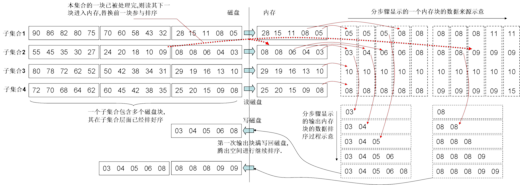 参见图示,内存块数为
参见图示,内存块数为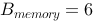 ,每块可装载
,每块可装载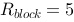 个元素,如果经过一个轮次的归并操作便能完成排序,则关于待排序元素集合的大小,下列说法正确的是_____。
个元素,如果经过一个轮次的归并操作便能完成排序,则关于待排序元素集合的大小,下列说法正确的是_____。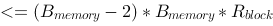
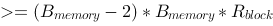
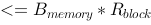
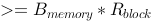
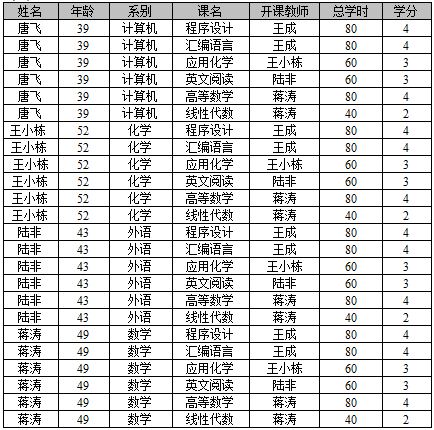
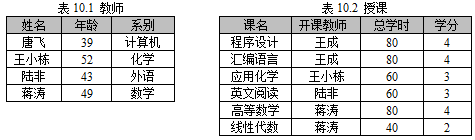 教师表用R表示,
教师表用R表示,  ,即 “教师”和“教师”关系的年龄不等“连接”操作结果是_____。
,即 “教师”和“教师”关系的年龄不等“连接”操作结果是_____。