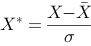题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友黄平
发布时间:2022-01-07

[单选题]
以下关于pandas数据预处理说法正确的是()。
A.pandas没有做哑变量的函数
B.在不导入其他库的情况下,仅仅使用pandas就可实现聚类分析离散化
C.pandas可以实现所有的数据预处理操作
D.cut函数默认情况下做的是等宽法离散化
 参考答案
参考答案
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
查看官方参考答案
 网友提供的答案
网友提供的答案
共位网友提供了参考答案,
查看全部
- · 有3位网友选择 D,占比37.5%
- · 有3位网友选择 A,占比37.5%
- · 有1位网友选择 B,占比12.5%
- · 有1位网友选择 C,占比12.5%



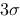 原则利用了统计学中小概率事件的原理
原则利用了统计学中小概率事件的原理