 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友mouster
发布时间:2022-01-06
[单选题]
假设有一个RDD的名称为words,包含9个元素,分别是:(”Hadoop”,1),(”is”,1),(”good”,1),(”Spark”,1),(”is”,1),(”fast”,1),(”Spark”,1),(”is”,1),(”better”,1)。则语句words.groupByKey()的执行结果得到的新的RDD中,所包含的元素是
A.(”Hadoop”,1),(”is”,(1,1,1)),(”good”,1),(”Spark”,(1,1)),(”fast”,1),(”better”,1)
B.(”good”,1),(”Spark”,1),(”is”,1),(”fast”,1)
C.(”good”,(1,1)),(”Spark”,(1,1,1)),(”is”,1),(”fast”,1)
D.(”Hadoop”,1),(”is”,1),(”good”,1),(”Spark”,1),(”is”,1)
 参考答案
参考答案
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
查看官方参考答案
 网友提供的答案
网友提供的答案
共位网友提供了参考答案,
查看全部
- · 有3位网友选择 B,占比33.33%
- · 有2位网友选择 A,占比22.22%
- · 有2位网友选择 D,占比22.22%
- · 有2位网友选择 C,占比22.22%



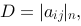 则
则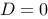 的必要条件是( )
的必要条件是( )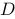 中有一列元素全为0
中有一列元素全为0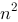 )
)





























