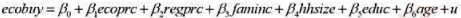题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友wu28wu28
发布时间:2022-01-06
[单选题]
下列数据整理和显示方法中,取值不可能大于1的是()。
A.比率
B.频数
C.累积频数
D.比例
 参考答案
参考答案
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
查看官方参考答案
 网友提供的答案
网友提供的答案
共位网友提供了参考答案,
查看全部
- · 有4位网友选择 A,占比40%
- · 有2位网友选择 C,占比20%
- · 有2位网友选择 B,占比20%
- · 有2位网友选择 D,占比20%



 时取值0。换言之, 在给定价格下, eco buy标志着一个家庭是否购买环保苹果。多大比例的家庭声称要购买环保苹果?
时取值0。换言之, 在给定价格下, eco buy标志着一个家庭是否购买环保苹果。多大比例的家庭声称要购买环保苹果?