 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友zhyjhyj
发布时间:2022-01-07
[主观题]
为了判断[图]和[图]哪个模型更好地拟合了数据,我们不...
为了判断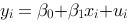 和
和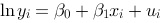 哪个模型更好地拟合了数据,我们不能使用
哪个模型更好地拟合了数据,我们不能使用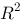 的原因是
的原因是
A、当0<y<1时,<img data="501606">会是负数
B、在这两个模型中,SST的单位不一样
C、在对数线性模型中,斜率系数的含义发生了变化
D、在对数线性模型中,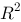 可能会大于1
可能会大于1
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
 抱歉!暂无答案,正在努力更新中……
抱歉!暂无答案,正在努力更新中……

 和
和 哪个模型更好地拟合了数据,我们不能使用
哪个模型更好地拟合了数据,我们不能使用 的原因是
的原因是 可能会大于1
可能会大于1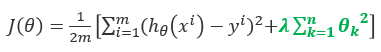 则下列说法正确的有
则下列说法正确的有





























