 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
提问人:网友vanehe668
发布时间:2022-01-06
[主观题]
在网上市场调研数据分析中,常用的拟合回归线的原则,是使各点与该线纵向距离的平方和为()。
A.适中
B.为零
C.最大
D.最小
 简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
查看官方参考答案
题目内容
(请给出正确答案)
A.适中
B.为零
C.最大
D.最小
简答题官方参考答案
(由简答题聘请的专业题库老师提供的解答)
 更多“在网上市场调研数据分析中,常用的拟合回归线的原则,是使各点与该线纵向距离的平方和为()。”相关的问题
更多“在网上市场调研数据分析中,常用的拟合回归线的原则,是使各点与该线纵向距离的平方和为()。”相关的问题
A.在客户关系的维护上更具价值
B.在网上市场调研上是最常用的方式之一
C.不能完整地完成营销过程,需要其他营销方式配合
D.是营销推广效果较为突出的方式之一
下列关于最小二乘法求实验的直线方程的说法中正确的有:
A.用数学解析的方法,从一组实验数据中找出一条最佳拟合曲线,称为方程的回归。回归法中最常用的方法是最小二乘法;
B.最小二乘法的原理是:若能找到一条最佳的拟合曲线,那么各测量值与这条拟合曲线上对应点之差的平方和为最小;
C.对于一元线性回归方程中的待定系数a和b,一般来说,如果实验点对直线的偏离大,它们的误差也大,由此定出的经验公式可靠程度就低;
D.对于一元线性回归,相关系数r的值在-1到1之间,如果r越接近于0,则说明实验数据的线性化程度越高。
利用MURDER.RAW中的数据。
(i)利用1990年和1993年的数据,用混合OLS估计方程
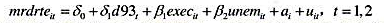
并以常用形式报告结论。不必担心通常的OLS标准误因a,的出现而不适当。你估计出了死刑的威慑效应吗?
(ii)计算FD估计值(只使用1990~1993年的差分;在FD回归中,你应该有51个观测)。现在,你对威慑效应有何结论?
(iii)在第(ii)部分的FD回归中,求残差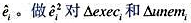 的布罗施-帕甘回归,并计算异方差性的F检验。同样做怀特检验的特殊情形[即将对
的布罗施-帕甘回归,并计算异方差性的F检验。同样做怀特检验的特殊情形[即将对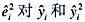 回归,其中拟合值得自第(ii)部分]。你对FD方程中的异方差性有何结论?
回归,其中拟合值得自第(ii)部分]。你对FD方程中的异方差性有何结论?
(iv)做第(ii)部分中的同样回归,但求异方差-稳健的t统计量。结果如何?
(v)你认为Aexec;的哪个统计量更值得信赖,是通常的:统计量还是异方差-稳健的!统计量?为什么?
(i)利用表13-1中同样的变量估计kids的一个泊松回归模型。解释y82的系数。
(ii)保持其他因素不变,黑人妇女和非黑人妇女在生育上的估计百分数差异是多少?
(iii)求σ。有过度散布和散布不足的证据吗?
(iv)计算泊松回归中的拟合值和作为kidsi和kidsi之相关系数平方的R2。并与线性回归模型中的R2相比较。
利用MEAP00 O1中的数据回答本题。
(i)使用OLS估计模型
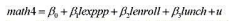
并用通常的格式报告你的结论。在5%的显著性水平上,每个解释变量都是统计显著的吗?
(ii)求出第(i) 部分中回归的拟合值。拟合值的取值范围是多少?它与math4的实际数据取值范围相比如何?
(iii)求出第(i)部分中回归的残差。哪类学校具有最大的(正)残差?对这个残差给予解释。
(iv)在方程中增加所有解释变量的平方项,检验它们的联合显著性。你会把它们放到模型中吗?
(v)回到第(i)部分中的模型,将因变量和每个解释变量都除以各自的样本标准差,并重新进行回归。(除非你还将每个变量分别减去了各自的均值,否则还应该包括一个截距项。)以标准差为单位,哪个解释变量对数学考试通过率具有最大的影响?
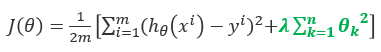 则下列说法正确的有
则下列说法正确的有
则下列说法正确的有
则下列说法正确的有A、等号右边第一项的目标是使模型能更好地拟合训练数据
B、等号右边第二项是正则化项,目的是控制过拟合现象
C、λ 是正则化参数(regularization parameter),用于控制等号右边两项的平衡
D、过拟合是指学习到的模型在训练集上也许误差较小,但是对于测试集中之前未见样本的预测却未必有效。或者通俗地说,模型过度学习了训练数据。
A.利用均值测度一组数据的集中趋势
B.利用抽样调查数据推断城镇居民平均收入
C.利用样本信息推断消费者对某品牌的知晓度
D.利用最小二乘法拟合线性回归模型


 警告:系统检测到您的账号存在安全风险
警告:系统检测到您的账号存在安全风险
为了保护您的账号安全,请在“简答题”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!



























